Розділ 5
Розслідування з використанням баз даних: перевірка якості даних
 Джанніна Сегніні – запрошена професорка у Школі Журналістики Колумбійського університету міста Нью-Йорк. До лютого 2014 року Сегніні очолювала команду журналістів і програмістів у La Nacion (Коста Ріка). Її команда публікувала розслідування, побудовані на зборі, аналізі та візуалізації баз даних. Із початку 2000 року Сегніні займалася навчанням сотень журналістів на території Латинської Америки, США, Європи та Азії в царині розслідувань і журналістики даних. Сегніні тричі була нагороджена Національною Премією з Журналістики імені Jorge Vargas Gene, Національною Премією з Журналістики імені Pio Vнquez, Почесною Премією з Журналістики імені Gabriel Garcнa Mбrquez, призом the Ortega y Gasset від щоденної газети El Paнs в Іспанії, премією за Краще Журналістське Розслідування у справах про корупцію від Transparency International для Латинської Америки й Карибських островів (TILAC), а також премією імені Maria Moors Cabot від Колумбійського Університету. Сегніні також була учасником і володарем премії Nieman Fellow (2001-2002) при Гарвардському університеті.
Джанніна Сегніні – запрошена професорка у Школі Журналістики Колумбійського університету міста Нью-Йорк. До лютого 2014 року Сегніні очолювала команду журналістів і програмістів у La Nacion (Коста Ріка). Її команда публікувала розслідування, побудовані на зборі, аналізі та візуалізації баз даних. Із початку 2000 року Сегніні займалася навчанням сотень журналістів на території Латинської Америки, США, Європи та Азії в царині розслідувань і журналістики даних. Сегніні тричі була нагороджена Національною Премією з Журналістики імені Jorge Vargas Gene, Національною Премією з Журналістики імені Pio Vнquez, Почесною Премією з Журналістики імені Gabriel Garcнa Mбrquez, призом the Ortega y Gasset від щоденної газети El Paнs в Іспанії, премією за Краще Журналістське Розслідування у справах про корупцію від Transparency International для Латинської Америки й Карибських островів (TILAC), а також премією імені Maria Moors Cabot від Колумбійського Університету. Сегніні також була учасником і володарем премії Nieman Fellow (2001-2002) при Гарвардському університеті.
Ніколи раніше журналісти не мали доступу до такої кількості інформації. Понад три ексабайти даних – еквівалент 750 мільйонів DVD-дисків – створюються щодня, і це число кожні 40 місяців подвоюється. Глобальне виробництво даних вимірюється нині йотабайтами (один йотабайт дорівнює 250 трильйонів DVD з даними). Уже йдуть обговорення щодо нових вимірів, необхідних після того, як ми переступимо поріг вимірювання йотабайтами.
Зростання обсягів і швидкості виробництва даних може приголомшливо впливати на багатьох журналістів, багато з яких не звикли використовувати для досліджень і викладу такі великі обсяги інформації.
Але терміновість і готовність використовувати дані та технології для їхньої обробки не повинні відволікати нас від базового прагнення до точності. Аби повною мірою зрозуміти значення даних, ми повинні вміти бачити різницю між сумнівною та якісною інформацією, а також уміти знаходити серед усього цього шуму реальні історії.
Важливий урок, який я засвоїла за два десятиліття використання даних для розслідувань, полягає в тому, що дані брешуть. Брешуть так само, як люди, або й більше, адже їх часто створюють і підтримують люди.
Дані призначені для зображення реальності в конкретний момент часу. Як же ми можемо перевірити, чи відповідає набір даних реальності?
Є два ключові завдання щодо перевірки інформації в розслідуваннях, де дані відіграють основну роль: первинна оцінка повинна проводитися відразу ж після отримання даних, а висновки з даних перевіряються в кінці розслідування або на етапі аналізу.
Первинна перевірка інформації
Правило перше – опитати геть-чисто всіх. Коли справа доходить до використання даних, такого поняття, як цілком надійне джерело, не існує.
Наприклад, чи повірите ви базі даних, опублікованих Світовим банком? Більшість журналістів, яким я ставила це запитання, сказали: «Так». Журналісти вважають Світовий банк надійним джерелом. Давайте перевіримо це припущення за допомогою двох наборів даних Світового банку, аби продемонструвати, як перевіряти дані, а також зміцнитися в думці, що навіть так звані «надійні джерела» можуть надавати помилкову інформацію. Я йтиму за процедурою, указаною в наведеному нижче графіку.
1.Чи маємо ми повний набір даних?
На початку занять я рекомендую вивчити крайні значення (високі або низькі) для кожної змінної в наборі даних, а потім порахувати, скільки записів (рядків) є в межах кожного з можливих значень.
Наприклад, Світовий банк публікує базу даних, де понад 10 000 незалежних оцінок по більш ніж 8600 проектів, розроблених цією організацією в усьому світі починаючи з 1964 року.
Лише за рахунок сортування в порядку зростання по стовпчику «Витрати на кредитування» ми можемо швидко переконатися, що в багатьох рядках у колонці «Вартість» значиться нуль.
Якщо створити зведену таблицю для підрахунку, скільки проектів мають нульову вартість, можна побачити, що більше половини з них (53 відсотки) мають нульову вартість.
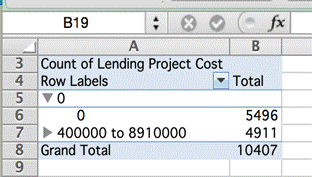
Це означає, що будь-хто, проводячи аналіз по країні, регіону або року з урахуванням вартості проектів, помилиться, якщо не візьме до уваги всіх записів без установленої вартості. Набір даних у тому вигляді, у якому він представлений, призведе до неточних висновків.
Банк публікує іншу базу даних, яка, імовірно, містить індивідуальні дані по кожному проекту, профінансованому (а не тільки оціненому) цією організацією починаючи з 1947 року.
Буквально відкривши на api.csv файл в Excel (версія станом на 7 грудня 2014 року), можна переконатися, що дані брудні й містять багато змінних, об’єднаних в одній ланці (наприклад, назви секторів і країн). Але ще більш промовистий факт, що цей файл не містить усіх проектів, профінансованих із 1947 року.
Бази даних фактично містять лише 6352 з більш ніж 15 000 проектів, профінанованих Світовим банком з 1947 року (банк урешті-решт виправив цю помилку. На 12 лютого 2015 року цей файл уже містив 16 215 записів).
Після невеликого проміжку часу, витраченого на вивчення даних, ми бачимо, що Світовий банк не включає до своїх баз даних вартість усіх своїх проектів, публікує брудні дані й не спромагається враховувати всіх своїх проектів як мінімум в одній версії даних. З урахуванням усього цього, якої якості даних варто очікувати від менш надійних установ?
Інший приклад невідповідності бази даних я знайшла під час семінару, який проводила в Пуерто-Ріко. Ми використовували базу даних державних контрактів Патентного відомства. 72 контракти за минулий рік мали в графі вартості негативні значення (-10 000 000 доларів).
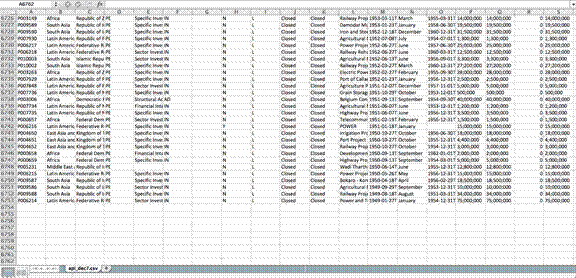
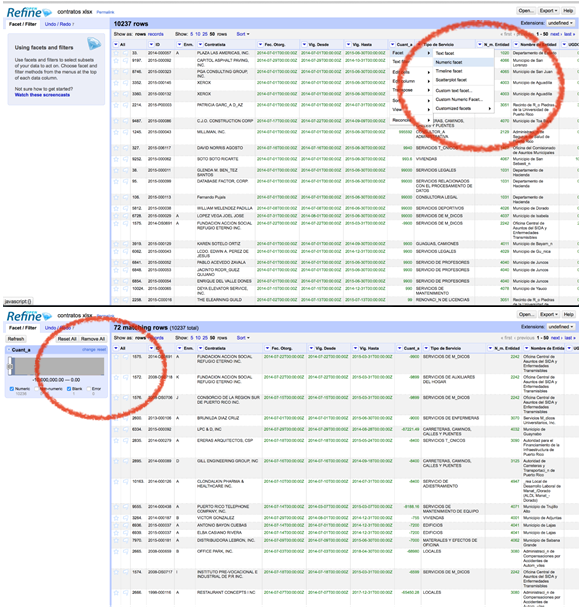
Чудовим засобом для швидкого перегляду й оцінки якості баз даних є Open Refine. На першій ілюстрації ви бачите, як створюється «числовий» фільтр для роботи з полем Cuantía (сума). Цей фільтр групує ланки з певним діапазоном значень. Це дозволяє вам вибрати будь-який діапазон, який охоплює потрібну послідовність добірок даних.
Друга ілюстрація показує, як ви можете сформувати гістограму з діапазоном значень, включених у базу даних. Записи можуть бути відфільтровані за значеннями шляхом переміщення стрілок усередині графіка. Те ж саме може бути зроблено щодо дат і текстових значень.
- Чи є дублікати записів?
Однією з поширених помилок, яких припускаються під час роботи з даними, є невиявлення повторюваних записів.
При обробці неструктурованих даних або інформації про людей, компанії, події чи то операції першим кроком має бути пошук унікального ідентифікатора для кожного елемента.
У випадку з базою даних проектів Світового банку кожен проект ідентифікується за допомогою унікального «ID проекту». Бази даних інших структур можуть містити унікальний ідентифікаційний номер або, у разі державних контрактів, номер контракту.
Якщо порахувати, скільки записів є в базі за кожним проектом, ми бачимо, що деякі з них повторюються до трьох разів. Тому будь-який розрахунок на основі кожної країни, регіону або дати без усунення дублікатів призведе до помилкових висновків.
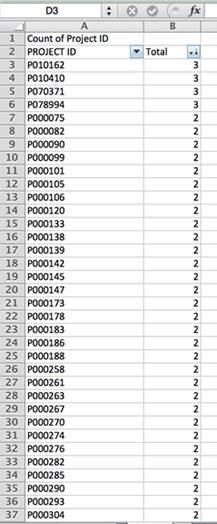
Записи дублюються, адже кілька типів оцінки виконані для кожної з них. Аби виключити повтори, ми повинні вибрати, яка з усіх оцінок найнадійніша. У цьому прикладі найбільш достовірними здаються записи, відомі як «Звіти про атестацію [PAR]», оскільки вони найкраще ілюструють проведену оцінку. Вони розроблені Independent Evaluation Group, яка самостійно й випадковим чином аналізує 25 відсотків проектів Світового банку за рік. Група відправляє своїх експертів «у поле», щоб оцінити результати цих проектів і провести незалежний аналіз.
- Чи точні представлені дані?
Один із найкращих способів оцінити достовірність набору даних – вибрати зразковий запис і порівняти його з реальністю.
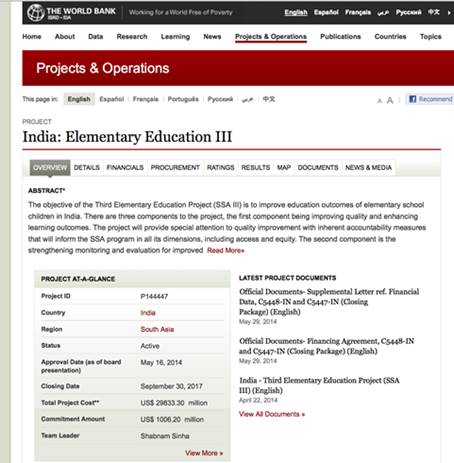
Якщо відсортувати базу даних Світового банку, яка нібито містить усі проекти, розроблені цією установою, в порядку зменшення вартості, то ми знайдемо проект в Індії, який був найдорожчим. У списку він фігурує з загальною сумою 29 833 300 000 доларів.
Якщо пошукати унікальний номер проекту (P144447) в Google, то можна отримати доступ до проектної документації, де фігурує вартість кредиту – 29 833 мільйонів доларів. Це означає, що цифра точна.
Цю вправу з перевірки даних через значущий зразок записів рекомендується повторювати систематично.
- Оцінка цілісності даних
З моменту введення в комп’ютер до моменту нашої роботи з цією інформацією дані проходять через кілька процесів введення, зберігання, передачі та реєстрації. На будь-якому етапі вони можуть зазнати маніпуляції з боку людей та інформаційних систем.
Нерідко буває так, що при цьому зв’язки між таблицями чи полями губляться або плутаються, а деякі змінні з тієї чи іншої причини не оновлюються. Тому вкрай важливо проводити тести на цілісність.
Наприклад, не так уже й рідко можна знайти проекти, зазначені в базі даних Світового банку як «активні» через багато років після дати їхнього затвердження, навіть за умови очевидної ймовірності, що багато з них уже втратили цей статус.
Для перевірки я створила зведену таблицю та згрупувала проекти по року їхнього затвердження. Потім я відфільтрувала дані, аби показати тільки ті, що у стовпчику «статус» відзначені як «активні». Ми бачимо, що 17 проектів, затверджених у 1986, 1987 та 1989 роках, досі числяться в базі даних активними. Майже всі знаходяться в Африці.
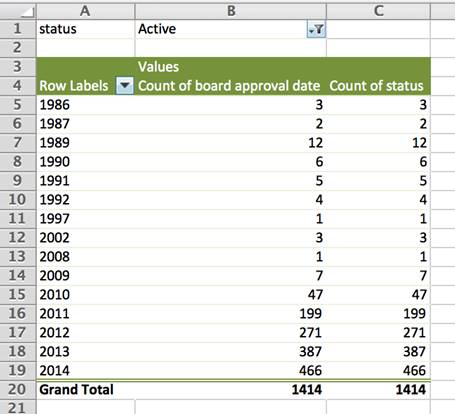
У цьому випадку необхідно з’ясувати безпосередньо у фахівців Світового банку, чи залишаються ці проекти активними через майже 30 років.
Для оцінки відповідності даних Світового банку ми могли б, звичайно, провести й інші тести. Наприклад, було б непогано розглянути, чи всі одержувачі кредитів («позичальники») відповідають організаціям і/або фактичним урядам країн, перерахованих у графі «Назва країни», а також чи правильно вказані регіони, де розташовані ці країни (графа «Назва регіону»).
- Розшифровування кодів і скорочень
Чи не найкращий спосіб віднадити журналіста – це показати складну інформацію, заплутану спеціальними кодами й термінологією. Цей трюк люблять чиновники й непрозорі організації. Вони розраховують, що ми не розуміємо сенсу того, що вони нам розповідають.
Але ті ж самі коди й абревіатури можна використовувати для скорочення кількості символів в осередках і нормалізації обсягів даних, що зберігаються. Майже кожна система баз даних, неважливо, державна чи приватна, використовує коди або абревіатури для класифікації інформації.
По суті, майже всі люди, структури й речі в цьому світі мають один або кілька кодів, приписаних до них. Люди мають ідентифікаційні номери документів, номери соціального страхування, коди клієнтів банку, номери платника податків, номери карт авіапасажирів, номери студентських квитків, посвідчень співробітників тощо.
Наприклад, металеві стільці в світі міжнародної торгівлі проходять під кодом 940179. Кожен корабель у світі має унікальний номер IMO. Багато речей мають один, властивий тільки їм номер: об’єкти нерухомості, транспортні засоби, літаки, компанії, комп’ютери, смартфони, гармати, танки, таблетки, розлучення, шлюби …
Потрібно вчитися розшифровувати коди й розуміти, як вони використовуються, аби зуміти побачити логіку за базами даних і, що ще важливіше, їх відносини, зв’язки один з одним.
Кожен із 17 мільйонів вантажних контейнерів у світі має унікальний ідентифікатор, і ми можемо відстежити їх, якщо розуміємо, що перші чотири букви ідентифікатора пов’язані з власником. Власника ви можете знайти в цій базі даних. Так, ці чотири літери таємничого коду стають засобом для отримання детальнішої інформації.
База даних оцінених проектів Світового банку повна кодів і скорочень, але, на диво, ця установа не публікує жодного глосарію, що описує зміст усіх цих абревіатур. Деякі акроніми є навіть застарілими й наводяться лише у старих документах.
Колонка «Інструмент кредитування», наприклад, класифікує всі проекти в залежності від 16 типів кредитних інструментів, які використовуються Світовим банком: APL, DPL, DRL, ERL, FIL, LIL, NA, PRC, PSL, RIL, SAD, SAL, SIL, SIM, SSL і TAL. Щоб осмислити ці дані, необхідно досліджувати значення цих абревіатур. В іншому випадку ви не знатимете, що, скажімо, ERL відповідає екстреним кредитам для країн, які недавно зазнали збройного конфлікту або стихійного лиха.
Коди SAD, SAL, SSL і PSL належать до спірної програми Структурної перебудови Світового банку, яку застосовували протягом 80-х і 90-х років. Вона надавала позики країнам у час економічної кризи в обмін на внесення цими країнами змін у свою економічну політику з метою скорочення бюджетних дефіцитів. Програма була поставлена під сумнів через неоднозначний вплив на розвиток суспільства, що мав місце в ряді країн.
За даними Банку, з кінця 90-х вона стала більш орієнтована на кредити для «розвитку», ніж на кредити на «реструктуризацію». Однак згідно з базою даних, між 2001 і 2006 роками понад 150 кредитів були відзначені кодом «Структурна перебудова».
Це помилки в базі даних чи програма Структурної перебудови продовжена на наступне століття?
Цей приклад показує, як розшифровка абревіатур служить не тільки адекватнішій практиці оцінки якості даних, а й, що важливіше, стає в пригоді для пошуку сюжетів, що становлять суспільний інтерес.
Перевірка даних після проведеного аналізу
Кінцевий етап верифікації має спрямовуватися на ваші висновки та проведений аналіз. Це, мабуть, найважливіший етап перевірки – свого роду лакмусовий папірець для усвідомлення, чи є ваша історія або первісна гіпотеза правомірною.
У 2012 році я працювала редактором у складі однієї міждисциплінарної команди в Ла Насьйон (Коста-Ріка). Ми вирішили дослідити одну з найважливіших державних субсидій від уряду, відому як Avancemos. Ця субсидія передбачала виплати щомісячних стипендій малозабезпеченим учням державних шкіл, щоб вони не кидали навчання.
Після отримання бази даних щодо всіх учнів-бенефіціарів ми додали туди імена їхніх батьків. Потім ми зробили запит на інші бази даних, що стосуються нерухомості, транспортних засобів, зарплат і компаній у країні. Це дозволило нам створити вичерпний перелік активів тих родин (ці дані в Коста-Ріці відкриті і стають доступні через Верховний суд у виборчих справах).
Наша гіпотеза полягала в тому, що дехто з тих 167 000 учнів-бенефіціарів жив не так уже й бідно, а тому не мав отримувати щомісячних виплат.
Перш ніж узятися за аналіз, ми подбали про те, щоб оцінити й очистити всі записи, а також перевірити відносини між кожною людиною та її активами.
Аналіз розкрив, що, серед іншого, батьки приблизно 75 учнів мали щомісячний дохід понад 2000 доларів США (мінімальний рівень заробітної плати для некваліфікованого робітника в Коста-Ріці становить 500 доларів) і що більше 10 тисяч із них мали у власності дорогу нерухомість або транспортні засоби.
Проте лише після відвідування їхніх осель ми змогли з’ясувати те, чого нам не могли б показати ніякі дані: ці діти справді жили у злиднях зі своїми матерями, адже їх кинули батьки.
Про їхніх батьків до призначення допомоги ніхто ніколи не питав. У результаті держава протягом багатьох років фінансувала з державних коштів освіту багатьох дітей, кинутих армією безвідповідальних батьків.
Ця історія узагальнює найкращий урок, який я отримала за роки моїх розслідувань з використанням даних: навіть найкращий аналіз даних не може замінити журналістики й польового контролю на місцях.