
Есть один аспект данных, которому сложно научиться и которому так же сложно учить: как привести ваши данные в удобоваримый вид, чтобы с ними было удобно работать. Есть несколько распространенных операций по подготовке данных, с которыми вы можете столкнуться, особенно если эти данные собирали не вы. Хотя большую часть работы по подготовке данных выполняют компьютеры, все же определить конкретные задачи необходимо вручную. По этой причине многие люди ненавидят эту часть работы с данными, но кто-то же должен делать грязную работу.
Не зависимо от того, кто вы − высокооплачиваемый аналитик данных с миллионом записей или частный предприниматель со списком контактов в 90 человек − в какой-то момент вы столкнетесь с бардаком в данных. К сожалению, подготовка данных − непростая задача, и здесь нет универсального рецепта. Каждый набор данных уникален, а некоторые техники можно использовать вообще только раз в жизни, как вы увидите на примерах ниже.
Разделение данных
Первая часть подготовки данных − разделение их на поля, с которыми будет удобно работать.
Приходилось ли вам когда-либо получать базы данных, в которых вы не могли получить прямой доступ к нужной информации? Возможно, в одной ячейке был указан полный адрес, так что вы не могли получить статистику о конкретных городах и штатах. Может быть, поставщик выслал вам инвентаризационную таблицу, содержащую 6000 пронумерованных деталей, но его система нумерации содержит складской номер и номер детали, а вам нужны только номера деталей.
| Вам нужно | Вам прислали |
| C77000S | GA3C77000S |
| W30000P | GA1W30000P |
| D21250G | DE1D21250G |
Давайте рассмотрим сложности со следующим набором данных:
| Торговый центр | Адрес | Город | Штат |
| Warm Willows Mall Peters Road Marrison, MI | |||
| Jaspers Martinson & Timberlake Rds Reed, FL | |||
| Lara Lafayette Shoppes 17 Industrial Drive Elm, CT |
Вы хотите, чтобы название торгового центра, адрес, город и штат были расположены в отдельных ячейках. База данных содержит информацию о сотнях торговых центров, и разбивать ее вручную займет массу времени. Названия торговых центров выделены жирным шрифтом, и это облегчает понимание, где собственно название, а где уже адрес. Однако не все адреса начинаются с цифр, поэтому никакой стандартный инструмент не распределит данные по отдельным ячейкам. Можно написать программу, которая будет распознавать жирный шрифт и отделять его от обычного, но поскольку это довольно редкая ситуация, вряд ли такая программа уже существует и доступна. Это как раз тот случай, когда вы (или кто-то другой для вас) можете написать программу, которая больше никогда вам не понадобится.
Мы не можем в этой главе научить вас всему, что касается разделения данных, поскольку каждая ситуация уникальна. Однако есть несколько стратегий, полезных во многих случаях. Мы рассмотрим некоторые из них, а также типичные проблемы и их причины.
Приступим
Простой пример задачи, с которой сталкиваются многие люди, − это разделение имен и фамилий. У вас может быть база данных, где имена и фамилии прописаны в одной ячейке, а вам нужно их отделить друг от друга. Или у вас уже могут быть отдельные ячейки для имен и фамилий, но в некоторых случаях имена с фамилиями все равно записаны вместе.
| Все в одной ячейке |
| Полное имя |
| Keith Pallard |
| Fumi Takano |
| Rhonda Johnson |
| Warren Andersen |
| Juan Tyler |
| Cicely Pope |
| В двух ячейках, но не все имена записаны правильно | |
| Имя | Фамилия |
| Keith Pallard | |
| Fumi Takano | |
| Rhonda | Johnson |
| Warren Andersen | |
| Juan | Tyler |
| Cicely | Pope |
Когда мы получаем базы данных в таком виде, решение видится довольно простым. Существуют традиционные способы отделения имен от фамилий для Keith, Fumi и Warren. Самый простой: найти пробел, разделить имя по пробелу − и готово!
Выглядит достаточно просто, но в реальности все становится сложнее. Что если в вашей базе данных тысячи строк? Вы потратите большое количество времени, разделяя имена вручную, к тому же существуют намного больше возможных вариаций полных имен, чем просто имя и фамилия.
| Инициалы в середине имени | Martina C. Daniels |
| Обозначения профессии | Lloyd Carson DVM (доктор ветеринарной медицины) |
| Двойные фамилии | Lora de Carlo |
| Звания, титулы | Rev (преподобный) Herman Phillips |
| Окончания | Jimmy Walford III |
| Фамилии, написанные через дефис | Tori Baker-Andersen |
| Фамилия, написанная перед именем | Kincaid Jr, Paul |
| Двойные имена | Ray Anne Lipscomb |
| Звания и титулы с окончаниями | Rev Rhonda-Lee St. Andrews-Fernandez, DD, MSW |
| Неверно включенная ячейка | Murray Wilkins 993 E Plymouth Blvd |
| Отсутствует имя | O’Connor |
| Отсутствует фамилия | Tanya |
| Вообще нет имени | |
| Черт знает что | JJ |
| Имя, принадлежащее не человеку | North City Garden Supply |
Что дальше? Найдем несколько решений
Предположим, нам нужно разделить полные имена, чтобы потом можно было сортировать список по фамилиям, и в нашем списке 500 человек (слишком много, чтобы заниматься этим вручную). Прежде чем начать, нужно кое-что выяснить:
- Почему так важно разобрать эту ячейку? Повредит ли чему-либо, если у нас будут полные имена в одной ячейке?
- Каким мы хотим видеть результат?
- Важно ли сохранить «Преподобный» («Rev.») и создать отдельную ячейку для титулов вроде доктор, миссис, капитан (Dr., Mrs., Capt.) и др.?
- Оставим «Jr» (младший) частью фамилии, или поместим это в отдельную ячейку?
- Надо ли оставлять инициалы в середине имени? Отправляем в отдельную ячейку или оставляем вместе с именем или фамилией?
- Надо ли сохранять обозначения профессии?
- Стоит ли тратить на это средства? В простых случаях, вы можете нанять кого-то для выполнения этой работы, но в сложных случаях это может не сработать. А если профессионал попросит за работу $1000?
- Что нам делать с неполными или неверными данными?
На эти вопросы стоит ответить до того, как вы начнете работать с данными. Если вы сразу ринетесь с места в карьер, то создадите еще больший хаос, да и ответы на эти вопросы могут облегчить процесс. Например, если вы решите, что обозначения профессии не важны, можно найти простой способ избавиться от них и упростить другие части проекта.
Допустим, вы работаете со списком из 20000 имен, из которых 19400 американские, а 600 − турецкие. Почтительное обращение в США ставится перед именем (например, Mr. John Smith), а в Турции − после (например, Jon Smith Bey). Вы пытаетесь выяснить, нужен ли отдельный раздел для данных о турках, и спрашиваете клиента о его предпочтениях.
Ответ прост. Ваш клиент не ведет бизнес в Турции и он не против, если вы удалите эти записи. ОТЛИЧНО! Осталось всего 19,400 записей.
Так как же нам разделить эти данные?
Существует такое количество техник, что мы могли бы написать отдельную книгу только на эту тему. Вы можете разделить данные в Excel или, если вы обладаете навыками программирования, можно использовать Python, SQL или любые другие языки. Информации слишком много для одной главы, так что обратите внимание на полезные ссылки в разделе «Источники». А пока мы рассмотрим некоторые базовые начальные стратегии, чтобы вы могли взяться за изучение этих ссылок, когда будете готовы.
Всегда делайте копию вашей базы данных, прежде чем начинать какие-либо манипуляции с ней, чтобы в случае ошибки была возможность вернуться к оригиналу.

ИЩИТЕ ЛЕГКИЕ ПУТИ
Во многих случаях, большая часть данных, требующих разделения, будет довольно простой. Вы можете обнаружить, что из 500 имен у 200 указаны имя и фамилия. Отложите их. Забудьте о них. Теперь посмотрите на оставшиеся 300.
НАЙДИТЕ СТРАННЫЕ СЛУЧАИ
Просмотрите свой набор данных на предмет ячеек без имен, со сложными, неполными, нечеловеческими именами, и прочими записями, с которыми вы не знаете, что делать. Отложите их. Предположим, их мы насчитали 40 штук.
ИЩИТЕ СХОДСТВА
Среди 260 оставшихся записей, возможно у 60 после имен стоят обозначения профессий. Работайте с ними всеми вместе, независимо от того, будете ли вы удалять эти обозначения, или переносить в отдельные ячейки. Когда вы удалите, или перенесете лишнее, то получите ячейки, где остались только имена. Те, которые содержат имена и фамилии, добавьте к тем 300, которые мы отложили в самом начале.
Двойные фамилии и прочие оставшиеся виды мы отправим к таким же группам.
РУЧНАЯ РАБОТА
40 странных случаев, которые мы обнаружили в начале, возможно, придется просто перенабрать вручную, в зависимости от того, что не так с каждой записью.
Иногда, когда мы работаем с данными в реальной жизни, записи сами разбираются со своими проблемами. Например, запись без имени оказывается дубликатом другой, полной записи. В таком случае, мы можем просто удалить неверную строку и продолжать дальше.
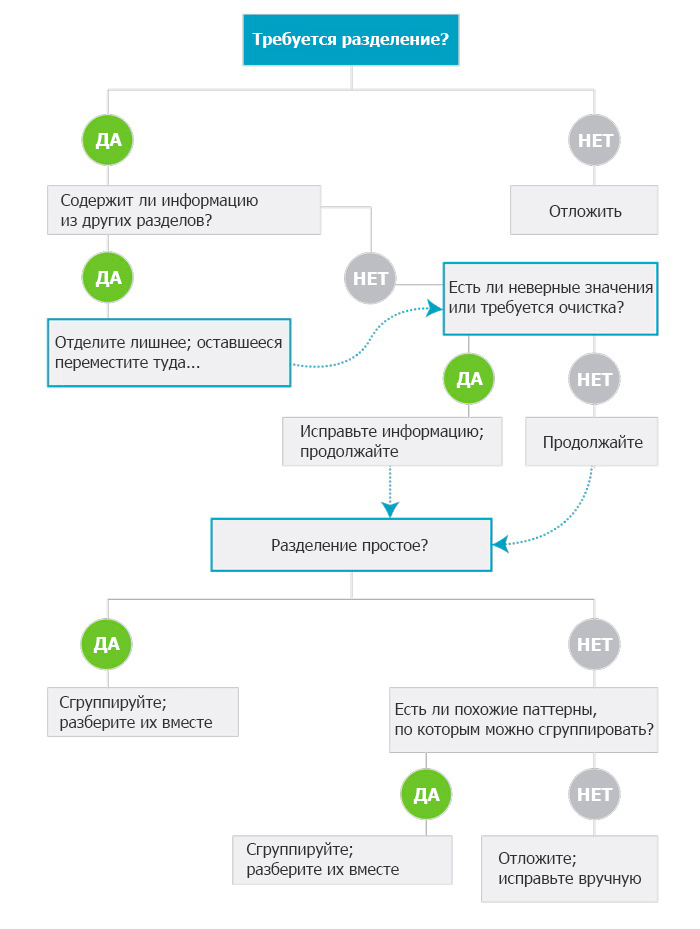
Распространенные проблемные поля
В зависимости от того, как были собраны данные, есть и другие поля, которые вы можете захотеть разделить, не только имена. Самые распространенные из них:
- адрес;
- телефонные номера, особенно если вы хотите отделить код;
- e-mail, если вас интересует информация о домене;
- дата, если вам нужен только год или месяц.
ЕДИНИЦЫ ИЗМЕРЕНИЯ И ИХ КОНВЕРТИРОВАНИЕ
Еще одно важное задание по подготовке данных − проверить, чтобы все данные в одном поле были представлены в одинаковых единицах. В идеале, вы определяете единицы измерения в форме заполнения, однако, вы можете работать с чужим набором данных, или же данные могут быть собраны их других источников, в которых информация составлялась машинами, измерявшими ее в определенных единицах. Например, у вас могут быть медицинские данные из разных стран, где в одних странах вес измерен в фунтах, а в других − в килограммах. Важно конвертировать все числа или в килограммы, или в фунты, чтобы они измерялись по одной шкале, иначе их нельзя будет сравнивать, и какую бы вы не делали визуализацию таких необработанных данных, она будет выглядеть довольно странно.
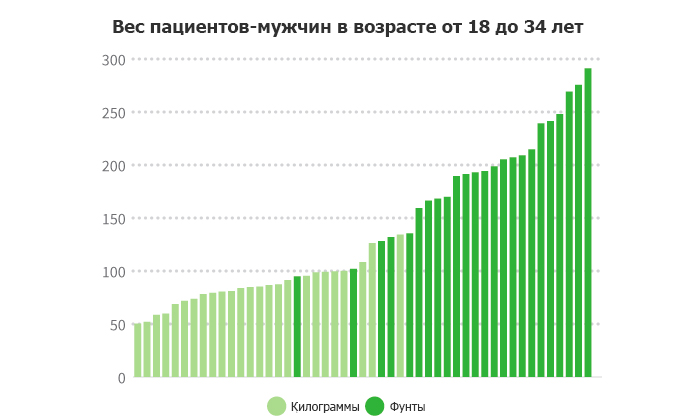
Вам следует просмотреть переменные в вашем наборе данных, чтобы определить разделы потенциально содержащие различные единицы измерения, чтобы понять, нужно ли их конвертировать. Если такие есть, то, возможно, нужно будет выделить отдельное поле, где указать оригинальные величины, которые вы будете конвертировать, чтобы знать, какие записи следует изменить. Если нет отдельного поля, фиксирующего единицы измерения, могут помочь другие поля, например, географическое расположение. Если вы не можете найти поле, из которого стали бы понятны величины, но подозреваете, что конвертирование необходимо, следует связаться с изначальным поставщиком данных, чтобы получить информацию. Может оказаться, что нет необходимости ничего конвертировать, а ваши данные просто странные, но лучше все же проверить и убедиться, чем проигнорировать возможную ошибку в данных.
Еще один тип конвертирования, иногда менее очевидный, − это конвертирование типов данных. Важно убедиться, что все данные в одном поле представляют собой один и тот же тип, иначе ваша визуализация может получиться неверной, в зависимости от того, как интерпретирует информацию ваше программное обеспечение. Например, «80» может для вас выглядеть числом, но компьютер может записать его как текстовую строку, а не число. Некоторые программы для визуализации распознают любой текст, напоминающий число, как число, другие программы − нет. В общем, полезно проверить, чтобы все поля (или переменные) были сохранены как данные одного типа − как текст или числа. Так вы будете уверены в том, что все, взятое из этого поля, машина будет воспринимать как нужный вам тип данных.
КОНТРОЛЬ НЕСООТВЕТСТВИЙ
Одной из самых трудоемких задач при очистке данных является работа с несовместимой информацией. Например, сегодня мы чаще встречаем базы данных с данными на различных языках, поскольку интернет позволяет легко собирать информацию от пользователей по всему миру. Иногда это может создавать проблемы, когда вы пытаетесь группировать объекты для визуализации, в зависимости от того, как разработана форма для входящих данных и какие данные из этого набора вы используете. Возможно, вы делаете опрос студентов колледжа, и одно из текстовых полей спрашивает об их профильной дисциплине. Один студент может ответить «Math» (сокращенно − «математика»), другой − «Mathematics» («математика»), а третий − «Applied Mathematics» («прикладная математика»). Вы знаете, что все эти ответы обозначают одну и ту же дисциплину, но компьютер или программа для визуализации не сгруппируют эти записи вместе. Вам придется создать один унифицированный термин (например, чтоб все говорили «Math» или «Mathematics») или создать отдельное запрограммированное поле, если вы хотите, чтобы все они воспринимались как часть одной и той же категории.
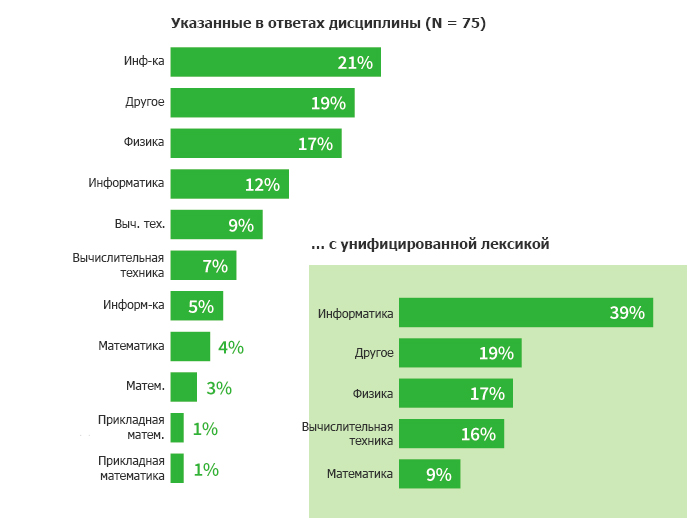
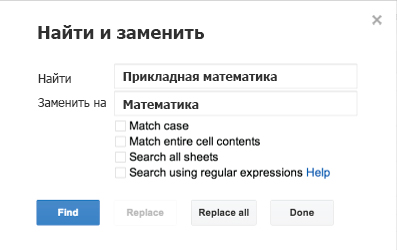
Хотя компьютер может здорово помочь с заменой значений, проблемы несоответствующих данных придется решать вручную, хотя бы частично. Если вы просматриваете текстовые поля, как и при программировании, лучше всего поможет “Найти и заменить”. Если вы знаете, какие основные варианты данных, которые вы хотите унифицировать, встречаются в базе данных, то можете быстро привести их все к единому варианту.
ОТСУТСТВУЮЩИЕ ЗНАЧЕНИЯ
Одна из самых раздражающих проблем − пустые или не полностью заполненные поля. Если данные не были собраны, возможно, вы сможете вернуться к источнику и заполнить пробелы, но возможно, что у вас больше не будет доступа к этому источнику. Возможно, вы не знаете, кто именно был источником информации, например, при анонимном опросе. Если у вас нет возможности получить эти данные, важно правильно поступить с отсутствующими значениями. Следует заранее задать значения, которые вы будете вставлять вместо отсутствующих, чтобы тот, кто будет иметь дело с вашим набором данных, знал, что данные для этого поля отсутствуют, а не пропущены потому, что их просто забыли вписать.
Эти значения должны находиться за пределами области ваших корректных данных, чтобы они четко обозначали отсутствие данных и ничего больше. Для баз данных, которые не работают с отрицательными числами, по умолчанию часто используется «-9», по крайней мере, в цифровых разделах. «999» также популярно для баз данных, которые не используют большие числа, а некоторые статистические программы используют точку (.) для баз данных с отрицательными и большими числами. Для текстовых полей в качестве индикатора отсутствующего значения обычно используют одно тире (−).
Помните, что отсутствующее значение − это не то же самое, что намеренный отказ от ответа! В обоих случаях, у вас нет ответа на вопрос, но когда кто-то активно выбирает не отвечать на вопрос, это тоже ответ, которого у вас не было бы, если бы вопрос был пропущен случайно. Эти данные не отсутствуют: вы точно знаете, что они есть, просто респондент не хочет с вами делиться ими. Как мы говорили в главе о разработке опроса, полезно включать вариант ответа «Предпочитаю не отвечать» для вопросов личного характера, например, о расовой или этнической принадлежности, доходах, политических предпочтениях и т.д. Таким образом, вы можете назначить определенный код для такого типа ответов, и когда позже будете просматривать свою базу данных, сможете различить, где респонденты целенаправленно выбрали не давать вам определенную информацию, и где просто отсутствуют данные.
Важно заметить, что для базовой описательной визуализации, отсутствующие значения описываются включением соответствующей категории («нет ответа») или изменением величины выборки. Однако, в индуктивной статистике, с отсутствующими данными могут поступать по-разному, от исключения до использования методов полного анализа, таких как ЕМ-алгоритмы.
МИНИМИЗАЦИЯ НАГРУЗКИ ПО ПОДГОТОВКЕ ДАННЫХ
Лучше как следует продумать все заранее. Если вы создаете форму для ответов, сделайте все возможное, чтобы избежать получения данных, с которыми придется много возиться на этапе подготовки. В главе о типах проверки данных мы поговорим о различных стратегиях минимизации количества задач по подготовке данных.
Если вы не занимаетесь сбором данных самостоятельно, но можете поговорить с теми, кто это делает, поработайте с ними, чтобы определить и разрешить проблемные точки сбора данных, используя в качестве руководства главу о типах проверки данных.
ПОСЛЕ ПОДГОТОВКИ ДАННЫХ
После того, как ваши данные разделены по нужным полям, конвертированы в необходимые величины и типы, а терминология − унифицирована, вы готовы приступать к фазе очистки данных, где вы займетесь проверкой реальных ошибок в данных. В следующих трех главах мы будем говорить о базовом процессе очистки данных, различных процессах проверки данных с целью идентификации проблем, и о том, что вы можете и чего не можете сделать с помощью очистки данных.