
Когда вы пытаетесь превратить данные в информацию, данные, с которыми вы начинаете работать, очень важны. Данные могут быть простыми фактоидами (результатами чьего-то анализа) или «сырыми» транзакциями, изучение которых целиком и полностью лежит на пользователе.

| Уровень агрегации | Количество показателей | Описание |
| Фактоиды | Максимальный контекст | Один из результатов обработки данных, без детализации |
| Ряды | Одна система показателей по одной стороне оси | Можно сравнить скорость изменения |
| Многоряды | Несколько систем показателей, общая ось | Можно сравнить скорость изменения, корреляцию между измерениями |
| Суммируемые многоряды | Несколько систем показателей, общая ось | Можно сравнить скорость изменения, корреляцию между измерениями, можно сравнить процент с общим количеством |
| Итоговые записи | Одна запись для каждой единицы многоряда. Показатели в других многорядах были каким-то образом агрегированы | Единицы можно сравнить |
| Отдельные транзакции | Одна запись для каждого случая | Никакой агрегации или комбинации, максимальная детализация |
Большинство наборов данных попадают на эти уровни агрегации. Если мы знаем, с данных какого вида нам придется начинать работать, мы сразу можем намного упростить задачу их правильной визуализации.
Давайте рассмотрим эти способы группировки данных по очереди, используя для примера потребление кофе. Предположим, что кафе учитывает каждую проданную чашку кофе и записывает два вида информации о продаже: пол покупателя и вид кофе (обычный, без кофеина или мокко).
Общая таблица таких данных по годам выглядит следующим образом (эти данные, кстати, полностью вымышлены):
| Год | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 |
| Всего продано | 19795 | 23005 | 31711 | 40728 | 50440 | 60953 | 74143 | 93321 | 120312 |
| Мужчины | 12534 | 16452 | 19362 | 24726 | 28567 | 31110 | 39001 | 48710 | 61291 |
| Женщины | 7261 | 6553 | 12349 | 16002 | 21873 | 29843 | 35142 | 44611 | 59021 |
| Обыкновенный | 9929 | 14021 | 17364 | 20035 | 27854 | 34201 | 36472 | 52012 | 60362 |
| Без кофеина | 6744 | 6833 | 10201 | 13462 | 17033 | 19921 | 21094 | 23716 | 38657 |
| Мокко | 3122 | 2151 | 4146 | 7231 | 5553 | 6831 | 16577 | 17593 | 21293 |
Фактоид
Фактоид − это часть общей информации. Фактоид рассчитывается из исходных данных, но акцент делается на конкретной детали.
Ряд (series)
Это когда один вид информации (зависимая переменная) сравнивается с другим (независимая переменная). Часто в роли независимой переменной выступает время.
| Год | 2000 | 2001 | 2002 | 2003 |
| Всего продано | 19795 | 23005 | 31711 | 40728 |
В этом примере общее количество проданного кофе зависит от года. Поэтому год − это независимая переменная («выберите год, любой год»), а количество продаж − зависимая («в этом году потребление кофе составляет 23,005 чашек»).
Рядом также может быть другой набор непрерывных данных, например температура. Посмотрите на эту таблицу, которая показывает, сколько времени требуется взрослому человеку, чтобы получить ожог первой степени от горячей воды. Здесь температура воды − независимый показатель.
Правительственный меморандум США, комиссия по безопасности потребления продукции, Питер Л. Армстронг, 15.09.1978
| Температура воды °С(°F) | Время получения ожога 1 степени |
| 46.7 (116) | 35 минут |
| 50 (122) | 1 минута |
| 55 (131) | 5 секунд |
| 60 (140) | 2 секунды |
| 65 (149) | 1 секунда |
| 67.8 (154) | мгновенно |
Также это может быть ряд несвязной, но связанной информации в категории, такой как основные марки автомобилей, породы собак, виды овощей, или масса планет солнечной системы.
| Планета | Масса относительно массы Земли |
| Меркурий | 0,0553 |
| Венера | 0,815 |
| Земля | 1 |
| Марс | 0,107 |
| Юпитер | 317,8 |
| Сатурн | 95,2 |
| Уран | 14,5 |
| Нептун | 17,1 |
Во многих случаях ряды данных имеют одну и единственную зависимую переменную для каждой независимой переменной. Другими словами, существует только одно количество чашек кофе, выпитых за каждый год. Обычно эти данные отображают в виде гистограммы, временной последовательности (динамического ряда) или столбчатой диаграммы.
Всего продаж
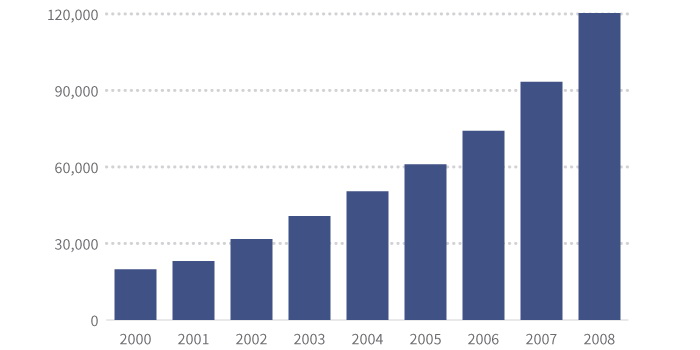
Если для каждой независимой переменной есть несколько зависимых, мы часто показываем информацию в виде диаграммы рассеивания или карты интенсивности, либо каким-то образом обрабатываем данные (например, определяем среднее значение), чтобы упростить то, что показываем. Мы вернемся к этому позже, когда будем говорить об использовании визуализации для демонстрации базовой дисперсии.
Многоряды
В многорядных данных есть несколько единиц зависимой информации и одна единица независимой информации. В этой таблице представлена информация о воздействии горячей воды, которую мы видели выше, однако она дополнена.
| Температура воды °С,(°F) | Время получения ожога 1 степени | Время получения ожога 2 и 3 степени |
| 46.7 (116) | 35 минут | 45 минут |
| 50 (122) | 1 минута | 5 минут |
| 55 (131) | 5 секунд | 25 секунд |
| 60 (140) | 2 секунды | 5 секунд |
| 65 (149) | 1 секунда | 2 секунды |
| 67.8 (154) | мгновенно | 1 секунда |
Давайте вернемся к нашему примеру с кофе − здесь может быть несколько рядов:
| Год | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 |
| Мужчины | 12534 | 16452 | 19362 | 24726 | 28567 | 31110 |
| Обыкновенный | 9929 | 14021 | 17364 | 20035 | 27854 | 34201 |
С таким набором данных мы знаем несколько фактов о 2001 годе. Мы знаем, что 16452 чашек было продано мужчинам, и что было продано 14021 чашку обычного кофе (с кофеином, сливками/молоком и сахаром).
Однако мы не знаем, как объединить эти данные в практических целях: они не связаны между собой. Мы не можем сказать, какой процент обычного кофе был продан мужчинам или сколько чашек досталось женщинам.
Иными словами, многорядные данные представляют собой просто несколько рядов одного графика или таблицы. Мы можем показать их вместе, но не можем укомплектовать или объединить так, чтобы это имело смысл.
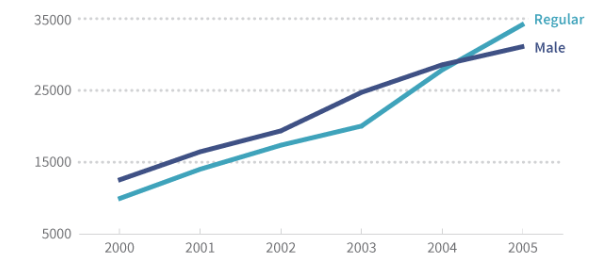
Суммируемые многоряды
Как следует из названия, суммируемые многоряды − это отдельный показатель (пол, вид кофе), разбитый на подгруппы.
| Год | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 |
| Мужчины | 12534 | 16452 | 19362 | 24726 | 28567 | 31110 | 39001 | 48710 | 61291 |
| Женщины | 7261 | 6553 | 12349 | 16002 | 21873 | 29843 | 35142 | 44611 | 59021 |
Поскольку мы знаем, что потребитель кофе может быть либо мужчиной, либо женщиной, то можем объединить эти показатели, чтобы получить более широкое видение потребления в целом. Прежде всего, мы можем продемонстрировать процентное соотношение.
Потребление кофе в 2001 году по гендерному признаку
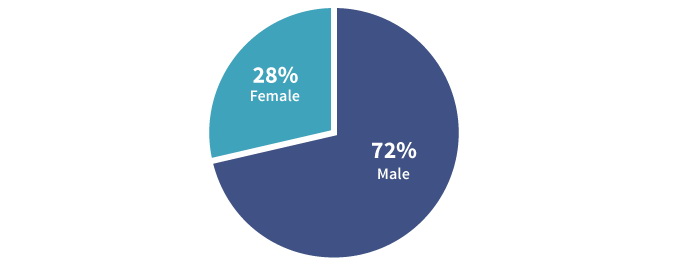
Кроме того, мы можем сложить сегменты и показать целостную картину:
Общее количество чашек кофе по гендерному признаку
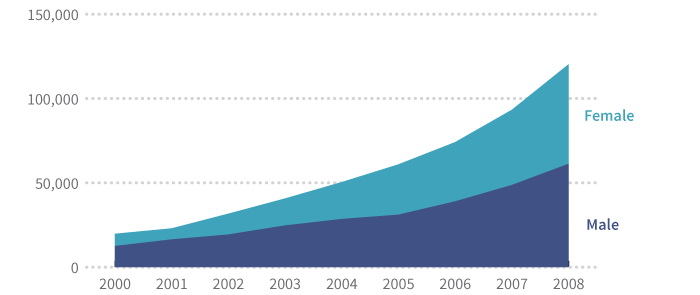
Сложность при работе с суммируемыми многорядами данных заключается в том, что необходимо знать, какие ряды совместимы друг с другом.
Например:
| Год | 2000 | 2001 | 2002 | 2003 | 2004 |
| Мужчины | 12534 | 16452 | 19362 | 24726 | 28567 |
| Женщины | 7261 | 6553 | 12349 | 16002 | 21873 |
| Обыкновенный | 9929 | 14021 | 17364 | 20035 | 27854 |
| Без кофеина | 6744 | 6833 | 10201 | 13462 | 17033 |
| Мокко | 3122 | 2151 | 4146 | 7231 | 5553 |
В этих данных нет ничего, что дало бы нам возможность объединить информацию. Необходимо человеческое понимание категорий данных, чтобы знать, что мужчины + женщины = полный набор, а также обычный кофе + кофе без кофеина + мокко = полный набор. Без этого знания мы не можем объединить данные или, что еще хуже, можем объединить их неправильно.
Даже если мы знаем значение этих данных и понимаем, что это две отдельные многорядные таблицы (одна по гендерному признаку, вторая − по типу кофе), мы не можем исследовать их глубоко. Например, мы не можем узнать, сколько женщин выпило обычный кофе в 2000 году.
Это распространенная (и существенная) ошибка. Многие люди склонны говорить, что:
- 36,7% чашек в 2000 году были проданы женщинам.
- В 2000 году было продано 9,929 чашек обычного кофе.
- Следовательно, 3,642.5 чашки обычного кофе были проданы женщинам.
Но это неверно. Такой логический вывод справедлив, только если вы знаете, что одна категория (тип кофе) равномерно распределена внутри другой категории (пол). Тот факт, что на выходе мы получили даже не целое число, говорит нам, что этот вывод неверен, поскольку никому не продают половину чашки.
Единственный способ серьезно проанализировать данные и задать новые вопросы (типа «Сколько чашек обычного кофе было продано женщинам в 2000 году?») − это иметь исходные данные. А дальше дело в понимании, как их правильно агрегировать.
Итоговые записи
Следующая таблица итоговых записей напоминает данные, которые могла бы сгенерировать система кассовых терминалов в кафе. Она включает колонку с категориальной информацией (пол, с двумя возможными вариантами) и промежуточные суммы для каждого типа кофе. Кроме того, в нее входят итоговые суммы для этих типов.
| Имя | Пол | Обычный кофе | Кофе без кофеина | Мокко | Итого |
| Боб Смит | М | 2 | 3 | 1 | 6 |
| Джейн Доу | Ж | 4 | 0 | 0 | 4 |
| Дейл Купер | М | 1 | 2 | 4 | 7 |
| Мэри Бруер | Ж | 3 | 1 | 0 | 4 |
| Бетти Кона | Ж | 1 | 0 | 0 | 1 |
| Джон Ява | М | 2 | 1 | 3 | 6 |
| Билл Бин | М | 3 | 1 | 0 | 4 |
| Джейк Битник | М | 0 | 0 | 1 | 1 |
| ИТОГО | 5М, 3Ж | 16 | 8 | 9 | 33 |
Такой тип таблицы знаком каждому, кто хоть немного работал с инструментами типа Excel. Мы можем провести некоторые подсчеты:
- Среди потребителей кофе 5 мужчин и 3 женщины.
- Они выпили 16 обычных кофе, 8 без кофеина и 9 мокко.
- Мы продали 33 чашки.
Но, что еще важнее, мы можем объединять категории данных, чтобы углубить наше исследование. Например, поинтересоваться − предпочитают ли женщины определенный вид кофе? Это именно то, в чем Excel действительно превосходен, и это можно сделать с помощью инструмента под названием «Сводная таблица».
Ниже приведена таблица, в которой представлено среднее количество чашек обычного кофе, кофе без кофеина и мокко, приобретенных клиентами обоих полов:
| Метки строк | Среднее количество мокко | Среднее количество кофе без кофеина | Среднее количество обычного кофе |
| Ж | 0,00 | 0,33 | 2,67 |
| М | 2,00 | 1,75 | 2,00 |
| Итого | 1,14 | 1,14 | 2,29 |
На этой таблице мы видим очевидную тенденцию: женщины любят обычный кофе, а мужчины равномерно разделились между всеми тремя типами кофе. Для подобного статистически достоверного заключения данных недостаточно. Но все эти данные так или иначе выдуманные, так что перестаньте так переживать по поводу потребления кофе.
Однако, главное в этих данных то, что они определенным образом были агрегированы. Мы суммировали их в нескольких плоскостях − по полу и типам кофе, агрегировав их по имени клиента. Хоть это и не исходные данные, они все же близки к ним.
Что действительно хорошо в таком суммировании, так это то, что набор данных остается довольно небольшим. Оно также предлагает способы исследования этих данных. Довольно просто найти данные опросов, которые выглядят подобным образом; например, Google Form может вытянуть подобные данные из следующей анкеты:
В электронной таблице Google мы получаем следующие данные:
| Время создания | Ваше имя? | Пол? | Обычный кофе | Без кофеина | Мокко |
| 1/17/2014 11:12:47 | Боб Смит | Мужчина | 4 | 3 |
Использование визуализации для выявления базовой дисперсии
Когда у вас есть суммируемые записи или исходные данные, обычным делом будет объединить их с целью упрощения их демонстрации. Показывая общее количество выпитого кофе (суммируя исходную информацию) или среднее количество чашек на одного клиента (среднее значение от исходной информации), мы делаем данные более простыми для понимания.
Обратите внимание на следующие транзакции:
| Имя | Мокко | Без кофеина | Обычный кофе |
| Боб Смит | 1 | 3 | 2 |
| Джейн Доу | 0 | 0 | 4 |
| Дейл Купер | 4 | 2 | 1 |
| Мэри Бруер | 0 | 1 | 3 |
| Бетти Кона | 0 | 0 | 1 |
| Джон Ява | 3 | 1 | 2 |
| Билл Бин | 0 | 1 | 3 |
| Джейк Битник | 1 | 0 | 0 |
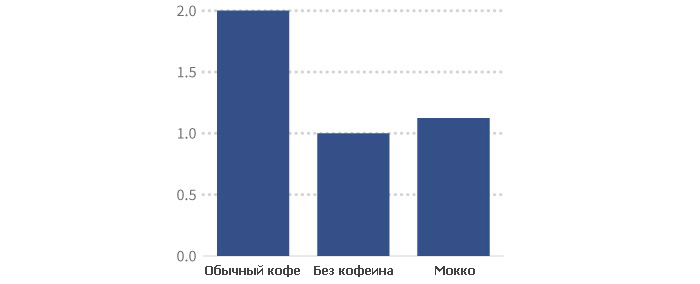
| ИТОГО | 9 | 8 | 16 |
| В среднем | 1.125 | 1 | 2 |
Мы можем показать среднее количество выпитых чашек кофе каждого типа в виде суммарного графика:
Среднее количество чашек
Но средние значения скрывают детали. Возможно, некоторые люди покупают одну чашку определенного типа кофе, а другие − несколько. Есть несколько способов визуализировать диапазон отклонений или дисперсию данных, которая демонстрирует исходную форму информации: например, графики интенсивности, гистограммы и графики рассеивания. Сохраняя исходные данные, вы можете получить в результате больше одной зависимой переменной для каждой независимой переменной.
Хорошая визуализация (например, гистограмма, которая подсчитывает, сколько людей вмещает каждая область или диапазон значений, составляющий в итоге среднюю величину) может обнаружить, что лишь несколько людей пьют много кофе, а большинство употребляет его в небольших дозах.
Взгляните на эту гистограмму, показывающую количество чашек кофе на каждого клиента. Мы всего лишь подсчитали, сколько людей выпивает одну чашку кофе, сколько − две, три, и так далее. Затем мы отразили в графике, как часто встречается каждое число (поэтому он и называется частотной гистограммой).
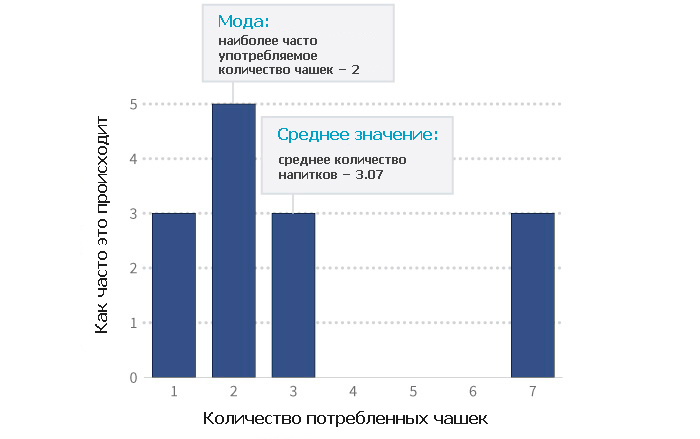
Среднее количество чашек в этом наборе данных − около 3. А величина наибольшей повторяемости, то есть самое часто употребляемое количество, − 2 чашки. Но, как показывает гистограмма, есть три заядлых кофемана, каждый из которых выпил по 7 чашек, увеличив таким образом среднее значение.
Другими словами, когда у вас есть исходные данные, вы видите исключения и выбросы (резко выделяющиеся значения) и можете более точно передать суть данных.
Даже эти данные, сколь бы подробными и информативными они ни были, не являются исходной информацией: они были агрегированы.
Агрегация происходит разными способами. Например, чек в ресторане обычно объединяет заказы по столу. Мы не можем узнать, что именно съел на ужин каждый конкретный человек за столом, только какие блюда подавали и сколько они стоили. Чтобы провести действительно глубокое исследование, нам нужны данные на уровне транзакций.
Отдельные транзакции
Транзакционные записи собирают данные о конкретном событии. Здесь не происходит агрегации данных вокруг какого-либо параметра, например чьего-то имени (хотя имя может входить в эти данные). Данные не накапливают во времени, они сиюминутны.
| Отметка времени | Имя | Пол | Кофе |
| 17:00 | Боб Смит | М | Обычный |
| 17:01 | Джейн Доу | Ж | Обычный |
| 17:02 | Дейл Купер | М | Мокко |
| 17:03 | Мэри Бруер | Ж | Без кофеина |
| 17:04 | Бетти Кона | Ж | Обычный |
| 17:05 | Джон Ява | М | Обычный |
| 17:06 | Билл Бин | М | Обычный |
| 17:07 | Джейк Битник | М | Мокко |
| 17:08 | Боб Смит | М | Обычный |
| 17:09 | Джейн Доу | Ж | Обычный |
| 17:10 | Дейл Купер | М | Мокко |
| 17:11 | Мэри Бруер | Ж | Обычный |
| 17:12 | Джон Ява | М | Без кофеина |
| 17:13 | Бил Бин | М | Обычный |
Эти транзакции можно агрегировать по любому из столбцов. По этим же столбцам можно создавать перекрестные ссылки. Отметки времени тоже можно объединить по отрезкам времени (по часам, дням или годам). В конце концов, первый набор данных о потреблении кофе по годам, который мы видели, является результатом этих исходных данных, правда, значительным образом обобщенных.
Выбираем способ агрегации
Когда мы накапливаем данные по областям или каким-то образом их преобразуем, мы убираем исходную историю. Например, когда мы превратили изначальные транзакции в итоги по годам:
- мы сделали данные анонимными, удалив имена клиентов во время агрегации;
- мы сгруппировали отметки времени, суммировав их по годам.
Любой из этих фрагментов данных мог бы показать нам, что некто является заядлым любителем кофе (основываясь на общем количестве кофе, купленном одним человеком, или на уровне потребления согласно с отметками времени). Хотя мы можем и не найти применения нашим данным потребления кофе, но что если данные относились бы, например, к употреблению алкоголя? Было ли бы у нас моральное обязательство предупредить кого-то, если бы мы увидели, что конкретный человек постоянно употребляет большое количество спиртного? А что, если он кого-то убил, сев пьяным за руль? Являются ли данные о потреблении алкоголя предметом общественного интереса для суда, в отличие от потребления кофе? Имеем ли мы право объединять одни данные и пренебрегать другими?
Справиться с этим может прогресс в сфере больших данных. Раньше хранение всех этих исходных транзакций требовало больших вычислительных ресурсов. И нам нужно было в процессе сбора данных решать, как их агрегировать, и избавляться от исходной информации. Но прогресс в эффективности хранения, параллельной и облачной обработке данных сделал реальностью моментальную агрегацию больших массивов данных. Это должно преодолеть некоторые погрешности агрегации.